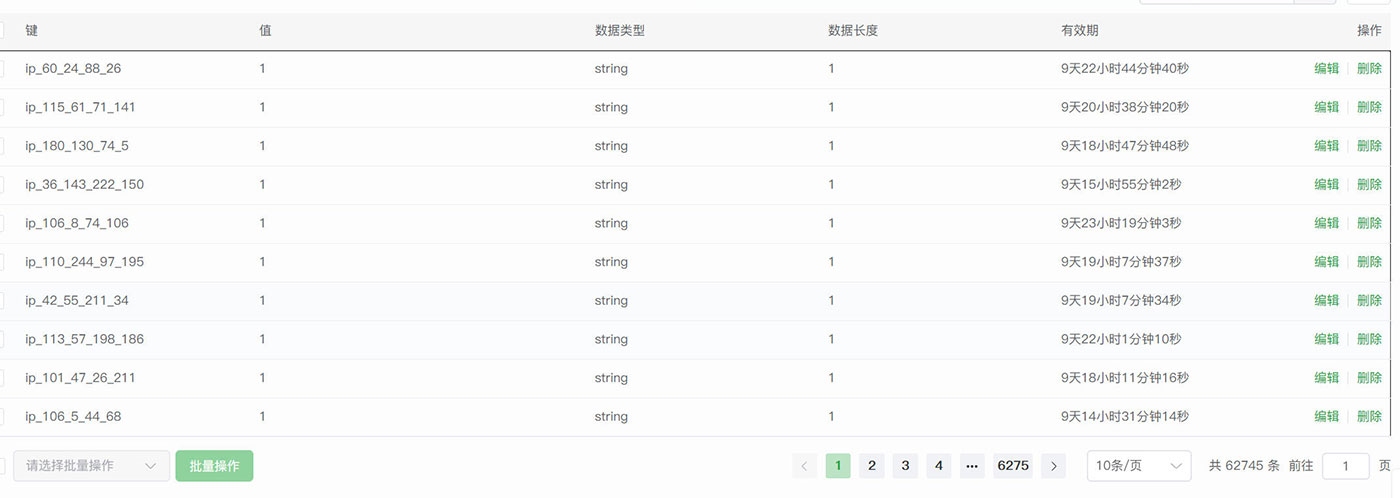
实际测试发现,在遇到几十万上百万异常IP的CC攻击访问时,fail2ban是有瓶颈的;如果把禁止时间设置过短,比如10分钟(600秒),根本起不到防护效果;如果把禁止时间设置过长,比如10天,可以起到防护效果,但是运行一段时间后,fail2ban会因为过载而崩溃;比如正在拦截的IP列表有几千或者上万的异常IP,崩溃后自己的服务器又变成一个裸机被攻击者攻击了。
想到的解决办法是,把禁止时间设置短一点,但是不能太短(fail2ban的拦截是从系统层拦截,响应速度更快),比如1个小时,保证fail2ban能稳定运行不崩溃;然后每次有异常IP拦截的时候,都触发一个将异常IP写入或者更新到Redis数据库的动作脚本,并根据服务器的负载情况设置记录数据的过期时间(Redis会在数据过期后自动清理),比如我的服务器目前攻击严重,我就设置为了拦截10天,10天后Redis自动清除被拦截的IP
具体脚本是通过网上千问等AI工具帮忙写的,确实还省了不少事,缩短了自己的短板
//如果没有安装Python脚本,先安装 //1、编写Redis写入脚本 //将这2个文件放到fail2ban的/etc/fail2ban/action.d目录 redis-ban.py //fail2ban在拦截异常IP的同时,将这个异常IP写入Redis数据库的Python实现脚本 redis-ban.conf //定义调用脚本配置文件 //2、在自定义配置文件/etc/fail2ban/etc/jail.local里添加(不会因为fail2ban升级覆盖掉自定义配置),使前面写的脚本自动运行 //原来规则action = %(action_)s 改成 action = %(action_)s redis-ban //3、重启或者重载fail2ban使自定义脚本生效 //第一次重启,重启后fail2ban的拦截会从零开始重新开始执行 systemctl restart fail2ban //后面如果修改了配置文件,可以直接重载配置,避免之前的统计清零 fail2ban-client reload
然后在具体的网站调用缓存类构造函数里写入异常IP过滤查询即可,排查逻辑是:
先验证当前IP是否是百度等蜘蛛爬虫,如果是则返回true,不做后面的检测;然后验证是否是禁止的爬虫,如果是则做后面的检测;然后再查看当前IP是否是在IP白名单列表,如果是则返回true,不做后面检测;最后检测当前IP是否在前面写入的Redis数据库里面,如果在,说明是异常IP,则返回false,不让访客访问网站后面的内容
具体实现代码参考之前一篇文章分享:《cc防护经验分享一:分享一个Redis缓存类,兼容redis和文件缓存》
private function __construct() {
//补充,如果IP在被禁止时间内,则禁止访问
if(!$this->_isAllowIp()){
//throw new Exception("抱歉,你的IP暂时不被允许访问!");
exit("抱歉,你的IP暂时不被允许访问!");
}
.....
}
这样做的好处是,虽然也是在应用层做的拦截,但是因为采用了Redis数据库,整体拦截速度会快很多;而且理论上时间越长,Redis数据库里存放的异常IP越多,效果会越好,而不会像之前,随着时间越久,因为fail2ban的数据库文件Sqlite存储是历史数据越来越大而导致fail2ban崩溃,拦截又被攻破。
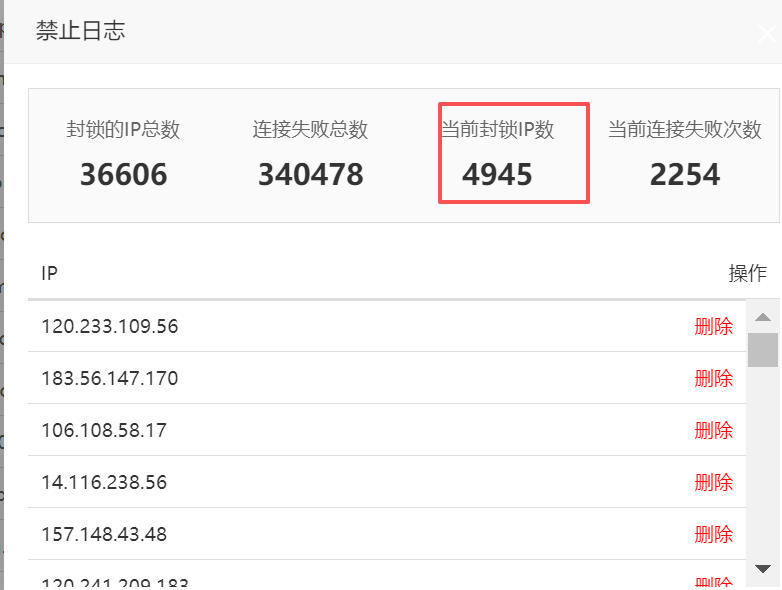
下图是我开启拦截后,不到半天的拦截数据,带宽逐渐由原来的高峰期50M降到10M以内了,防护效果非常明显。